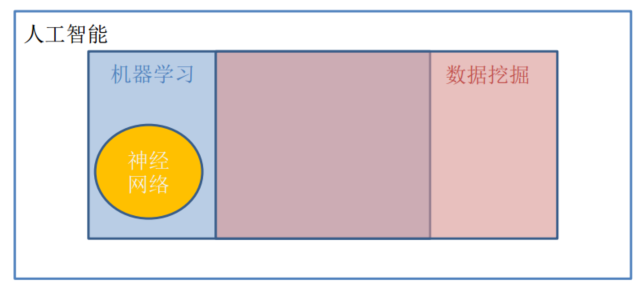
人工智能、机器学习,数据挖掘,神经网络之间的关系:
✎关于课程内容
✎实践的机器学习和数据挖掘技术
- 基本概念,核心工具
- 学习系统的框架, 优化方法, 分类, 回归, 聚类,关联规则,
链接分析
- 学习系统的框架, 优化方法, 分类, 回归, 聚类,关联规则,
- 主流技术,典型实际问题的解决方法
- 深度神经网络, Boosting/随机森林+决策树
- 并行化机器学习算法(大数据下的机器学习)
- 应用: 搜索引擎、推荐系统、图像搜索,量化交易等
- Kaggle, PASCAL VOC,腾讯社交广告预测比赛,百度快速人像
识别比赛经验分享
✎Machine Learning Part
- Optimization method(优化方法)
- Gradient descent(梯度下降)
- Stochastic gradient descent(随机梯度下降)
- Coordinate descent(坐标下降)
- Regression
- Linear regression(线性回归)
- Classification(分类)
- Logistic Regression (Parallelization)(逻辑回归(并行化))
- Boosting + decision trees, Random Forest (Parallelization)
- Deep Neural Networks(深度神经网络)
- Clustering(聚类)
- K-means
- Recommendation Systems(推荐系统)
- matrix factorization / field-aware factorization machines
✎Data Mining Part
- Association Rules
- Similarity Search
- Learning to hash
- Link Analysis
- Page Rank
✎背景
✎软件的现状
过去十多年,我们开发的软件系统主要是收集数据
- ERP系统=单据电子化
- 邮件系统=信件电子化
- 企业运作产生大量的数据
- 互联网的网页/图片/视频数据
- 互联网/移动应用中的用户行为数据
- 金融行情/交易数据,各种经济数据,上市公司财务数据
- 监控摄像头(小区,交通,商铺)或其他传感器产生的数据
- 医疗数据
- …
✎软件的未来
从收集数据到分析数据,市场上需要“聪明”的软件
- 能否给我推荐我喜欢的电影/衣服/新闻/游戏/朋友?
- 汽车/无人机能否自动驾驶?工业机器人能否代替工人?
- 机器能否理解图片内容、视频内容、自然语言?
- 机器能否代替人工决策?
- …
✎工业中的机器学习
-
大规模数据+人工特征+线性模型为主
- 高质量的人工特征(特征工程)+并行化训练+高吞吐量
预测 - 中等规模的数据,可用非线性模型(如Boosting+决策树,
随机森林)
- 高质量的人工特征(特征工程)+并行化训练+高吞吐量
-
深度学习
- 在一些难以获得高质量人工特征的应用中获得巨大成功
- 图像/视频/语音/自然语言理解,广告点击率预估
-
关键技术
-
并行化(分布式)学习算法,内存/训练时间限制
典型场景:给你1000台机器, 10000GB数据,要求你的算法在1小时内完
成训练 -
高吞吐量预测
典型场景:每个CPU每秒钟要完成800-1000个预测
-
模型稳定性
-
增量训练
-
-
机器学习人才需求
- Developer:负责实现并行化、高吞吐量的算法;特征工程
- Researcher:设计新的机器学习算法,提升算法的效果(如准确率)
✎应用成果
- 微软的“同声翻译”
- Google 的语言机器人助手
- AlphaGo 击败人类顶尖棋手
- 网页分类
- 垃圾邮件过滤
- 手写识别
- 人脸识别
- 搜索引擎结果排序
- 机器翻译
- 广告排序,广告推荐
- 相似图片搜索
- 相机中的人脸检测
✎基本概念
✎machine learning vs. data mining
- 机器学习:从数据中自动分析获得规律,并利用规律对未知数据进行预测
- 数据挖掘:“数据模型”的发现过程,即从数据中发现有用的“规律”
机器学习擅长的典型场景是人们对数据中的寻找目标(规律)几乎一无所知,例如Netflix电影推荐。但是,当挖掘的目标能够比较清楚地描述时,机器学习的方法并不成功。例如“在web上定位人们的简历”,基于规则的方法优于机器学习方法。
✎机器学习类型
-
有监督学习 (Supervised Learning):从标签化的训练数据集中推导出预测函数的过程,即对训练数据集中的每个样本,都给出对应的“正确答案”(标签 (label))。
可根据输出变量的类型分为
分类和回归两类:- 分类 (classification):离散变量预测,为定性输出;
- 回归 (regression):连续变量预测,为定量输出。
-
无监督学习 (Unsupervised Learning):从无标签的训练数据集中推导出预测函数的过程,即只给定训练数据集,不给结果(标签)。
- 聚类 (clustering):无监督学习的方法。聚类的结果是产生一组集合,一个集合中的对象与同集合中的对象彼此相似,与其他集合中的对象相异。
-
半监督学习 (Semi-supervised learning):有监督学习和无监督学习的中间带。对于半监督学习,其训练数据一部分是有标签的,另一部分没有,而且没标签的数据量一般远大于有标签的数据量(这符合现实情况)。隐藏在半监督学习下的基本规律:数据的分布必然不是完全随机的,通过一些有标签数据的局部特征,以及更多没标签数据的整体分布,就可以得到可以接受甚至是非常好的分类结果。
可根据不同的学习场景分为四大类:
- 半监督分类 (Semi-supervised classification):在无标签样本的帮助下使用有标签样本进行训练,获得比只用有标签样本训练得到的分类器性能更优的分类器,弥补有标签样本的数据量不足的缺陷,其中标签取有限离散值。
- 半监督回归 (Semi-supervised regression):在无标签样本的帮助下使用有标签样本进行训练,获得比只用有标签样本训练得到的回归器性能更优的回归器,弥补有标签样本的数据量不足的缺陷,其中标签取连续值。
- 半监督聚类 (Semi-supervised clustering):在有标签样本的信息帮助下,获得比只用无标签的样本得到的结果更好的簇,提高聚类的精度。
- 半监督降维 (Semi-supervised dimensionality reduction):在有标签的样本的信息帮助下找到高维输入数据的低维结构,同时保持原始高维数据和成对约束 (Pair-wise constraints) 的结构不变,即在高维空间中满足正约束 (Must-link constraints) 的样例在低维空间中相距很近,在高维空间中满足负约束 (Cannot-link constraints) 的样例在低维空间中距离很远。
开启 Machine Learning 学习之旅!